View Github Repo, Click Below:
Table of Contents
About the Project
Before deploying software products in the commercial space, developers need to ensure their products perform as intended. The process of verifying or evaluating their software products is known as software testing. A rather candid way of testing software would be to simply use it to identify any faults in the product. A more sophisticated and elaborate version of this is referred to as manual testing, where the tester follows a bunch of steps to verify the performance of the software for different scenarios/use-cases. An alternate and more efficient way of achieving the same purpose is automation testing, effectuated through automation software that uses programmable scripts. Katalon Studio, developed by Katalon Inc., is one such software tool.
Here’s an example of a simplified test script, written in the Groovy language, that automates the process of logging into the Katalon software and verifies whether the log-in is successful or not.
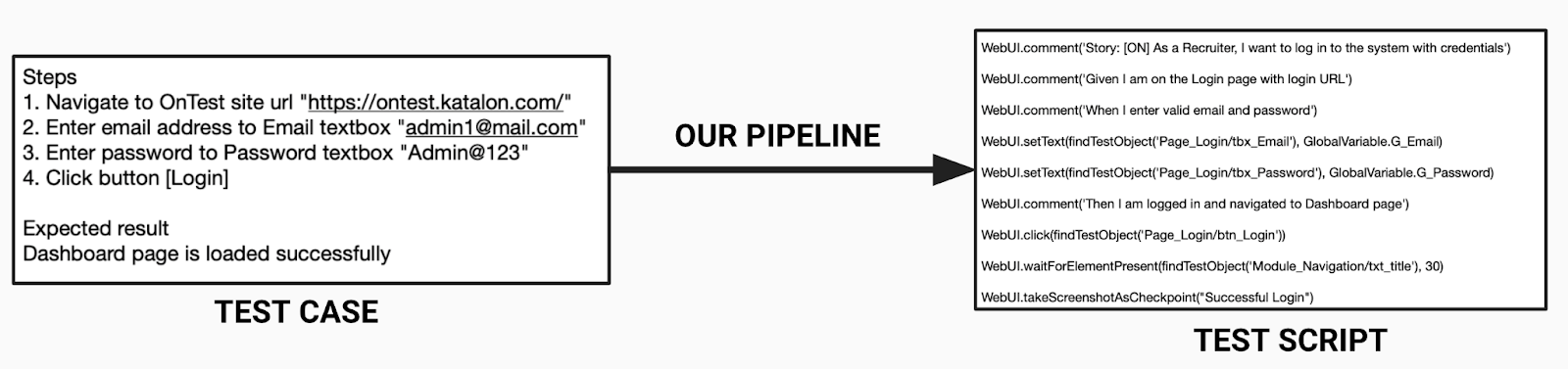
For this project, our objective was to help Katalon Studio in building an end-to-end pipeline that can automatically generate scripts that facilitate automation testing, from a list of steps for each possible scenario to test, collectively referred to as test cases, provided in natural language (English in this case).
Simply put, we aim to build a pipeline that can automatically translate manual test use-cases for a software, written in English, into an actionable script, which accelerates the process of automation testing and saves a lot of valuable time for the testers. Below is an illustration that encapsulates the gist of the pipeline we intend to build for the project.
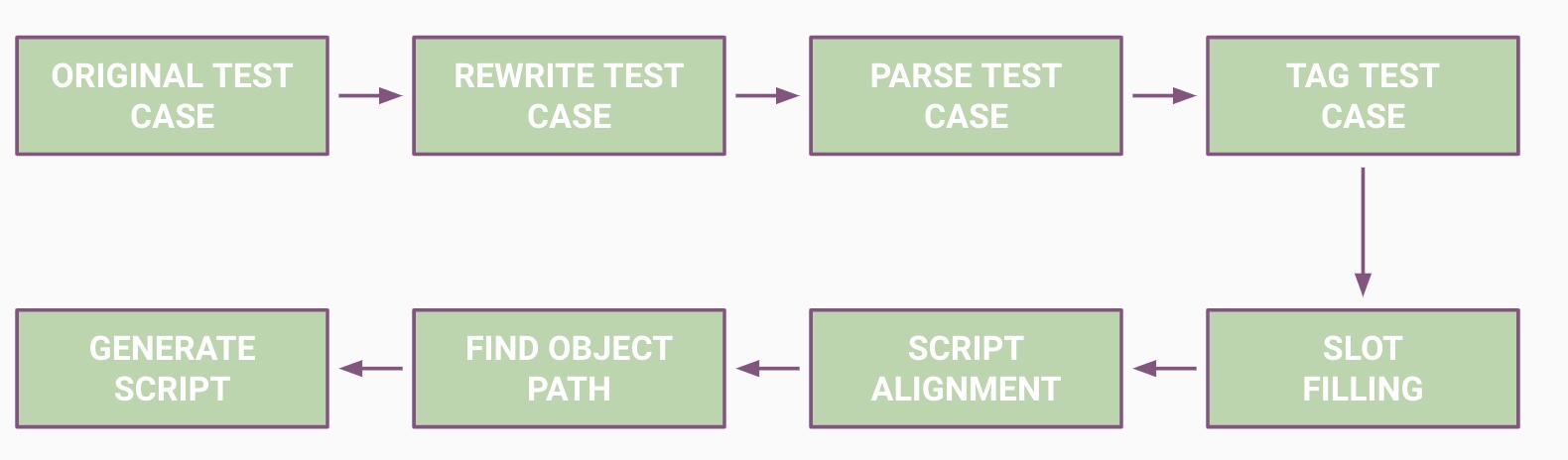
For the full report: click the link below:
Detailed Final Report
Getting Started
To get started, you will only need to install the requirements and fork/download the package, together with (description needed)
Prerequisites
To install the requirements, open the main notebook and un-comment the setup to install the required packages or run the following to have the same version as our environment:
pip install -r requirements.txt
If not working, open the requirements.txt and check if the required packages are installed.
For running the main notebook, if you want to use the trained tagger directly, you need to download the model pickle file and save it in the pickle_files/pickle_files_for_parsing/. (Sorry for the inconvenience as the tagger is too large to upload on Github.)
Usage
The main_notebook demonstrate how the whole pipeline works including Setup, Data, Tagging, Parsing, Test Scripts generation and Evaluation.
The util contains the details about the modules and functions.
For the data preprocess util, check the detailed instruction here
For the parsing util, check the detailed instruction.
For the BERT tagger, if you want to use the trained tagger directly, please download the model pickle file and save it in the pickle_files/pickle_files_for_parsing/. Another option is training the tagger in the main notebook.
For the script generation util, check the get_object_path_instruction util and script_generation_instruction util
For the evaluation util, check the details instruction here.
The different tagger notebooks show different methods of training the tagger to extract the entities of interest. BERT tagger is recommended for tagging task.
Evaluations
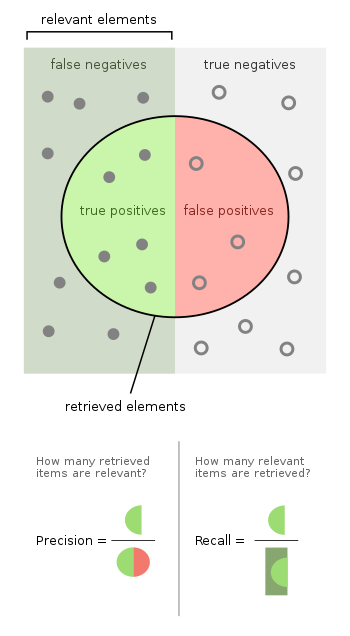
F1 Score
F1 one is a popular metric for evaluating the performance of classification models. The formula is shown above. Recall means of all the actual positive examples out there, how many of them did I correctly predict to be positive and it is calculated by the correct generated code chunks divided by (correct generated code chunks + code chunks not correctly generated=false negatives). And precision means of all the positive predictions I made, how many of them are truly positive. It is calculated by the correctly generated code chunks divided by all the generated code chunks (both right and wrong ones). F1 is one of the widely used metrics because it considers both precision and recall and calculates a balanced summarization of the model performance.
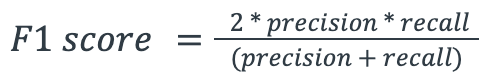
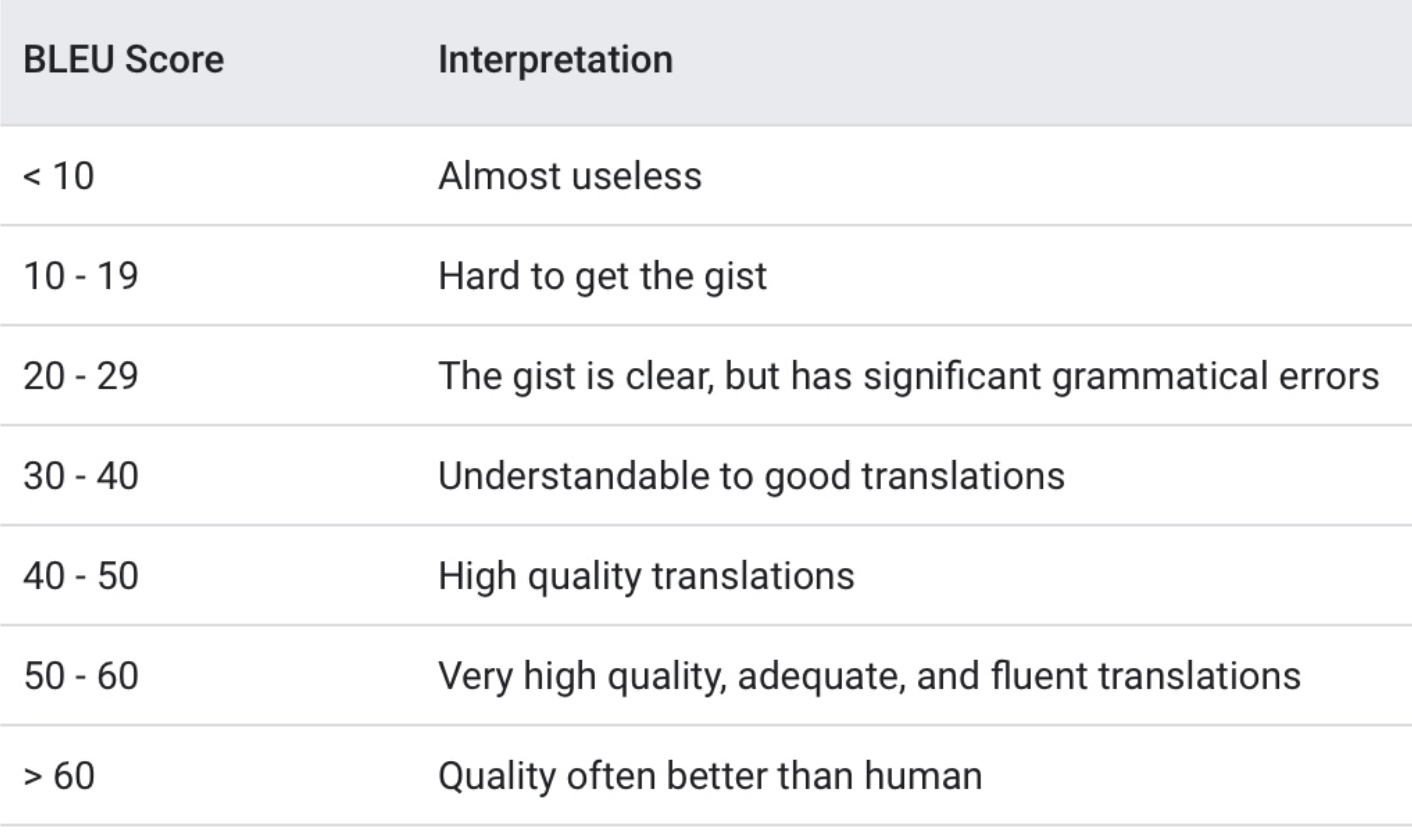
BLEU Score
BLEU (BiLingual Evaluation Understudy) is a metric for automatically evaluating machine-translated text. The BLEU score is a number between zero and one that measures the similarity of the machine-translated text to a set of high-quality reference translations. It is calculated by using n-grams precision and brevity-penalty.
Brevity Penalty
The brevity penalty penalizes generated translations that are too short compared to the closest reference length with exponential decay. The brevity penalty compensates for the fact that the BLEU score has no recall term.
N-Gram Overlap
The n-gram overlap counts how many unigrams, bigrams, trigrams, and four-grams (i=1,…,4) match their n-gram counterpart in the reference translations. This term acts as a precision metric. Unigrams account for adequacy while longer n-grams account for fluency of the translation. To avoid overcounting, the n-gram counts are clipped to the maximal n-gram count occurring in the reference

Documentation
References:
Building named entity recognition model using BiLSTM-CRF network: https://blog.dominodatalab.com/named-entity-recognition-ner-challenges-and-model
Text Classification with BERT in Pytorch: https://towardsdatascience.com/text-classification-with-bert-in-pytorch-887965e5820f
Named entity recognition with BERT in Pytorch: https://towardsdatascience.com/named-entity-recognition-with-bert-in-pytorch-a454405e0b6a
BiLSTM original paper: https://paperswithcode.com/method/bilstm
Flair official Github Repo: https://github.com/flairNLP/flair
What are Word Embeddings: https://machinelearningmastery.com/what-are-word-embeddings/
A comparison of LSTM and BERT in small dataset: https://arxiv.org/abs/2009.05451
CodeBLEU: https://arxiv.org/abs/2009.10297
Evaluation, BLEU: https://cloud.google.com/translate/automl/docs/evaluate
Recall: https://developers.google.com/machine-learning/glossary#recall
Precision: https://developers.google.com/machine-learning/glossary#precision
Libraries
os: https://docs.python.org/3/library/os.html
pandas: https://pandas.pydata.org/
numpy: https://numpy.org/
re: https://docs.python.org/3/library/re.html
nltk: https://www.nltk.org/
spacy: https://spacy.io/
textacy: https://textacy.readthedocs.io/en/latest/
pytorch: https://pytorch.org/
Levenshtein distance: https://pypi.org/project/python-Levenshtein/
Longest common substring: https://docs.python.org/3/library/difflib.html#difflib.SequenceMatcher
pickle: https://docs.python.org/3/library/pickle.html
collection: https://docs.python.org/3/library/collections.html
warnings: https://docs.python.org/3/library/warnings.html
Frame Definitions
{Verb: ‘Enter/Input’, Value: ? (value to be entered), Location: ? (location to enter the value)}
{Verb: ‘Click’, Value: ? (the object to be clicked on)}
{Verb: ‘Wait’, Value: ? (the object to wait for), Time: ? (the amount of time to wait)}
{Verb: ‘Get’, Value: ? (the object to extract)}
{Verb: ‘Check’, Value: ? (the correct value to be checked against)}